Coherency gathering in ray tracing
Saturday, Jan 21, 2023 · 1900 words · approx 9 mins to readPreamble
What follows is a lightly edited version of an article I wrote for the Imagination Technologies company blog, originally published on 11th February 2020 or thereabouts. It’s now attributed to Kristof Beets at the time of re-publishing here, because I no longer work there, but I was the original author.
The general thesis of the article is skewed towards Imagination’s implementation of ray tracing in their current GPU microarchitecture, but applies to any contemporary design today due to how ray tracing was specified in DXR, seeding the current processing and programming model, and overall ecosystem (Vulkan implements a very similar processing and programming model).
Since writing it, a couple of other vendors have come to market with a flavour of hardware-supported coherency gathering under application control. I now believe that a combination of transparent always-on hardware for it, plus application hints to the hardware about how best to work, is probably the best way to do it overall.
Introduction
Despite the theoretically infinite ways to implement a modern GPU, the truly efficient ways to make one come to life in silicon tend to force the hands of those making them for real. The reality of manufacturing modern high-performance semiconductors, and the problem at hand when trying to accelerate the current view of programmable rasterisation, have uncovered trends in implementation across the GPU hardware industry.
For example, SIMD processing and fixed-function texture hardware are a cast-iron necessity in a modern GPU, to the point where not implementing a GPU with them would almost certainly mean it wasn’t commercially viable or useful outside of research. Even the wildest vision of any GPU in the last two decades didn’t abandon those core tenets. (Rest in peace, Larrabee).
Real-time ray tracing acceleration is the biggest upset to the unwritten rules of the GPU in the last 15 years. The dominant specification for how ray tracing should work on a GPU, Microsoft’s DXR, demands an execution model that doesn’t really blend in with the way GPUs traditionally like to work, giving any GPU designer that needs to support it some serious potential headaches. That’s especially true if real-time ray tracing is something they haven’t been thinking about for the last decade or so and here at Imagination, we have been.
The key ray tracing challenges
If you make your way through the DXR specification and think about what needs to be implemented in a GPU in order to provide useful acceleration, you’ll quickly tease out a handful of high-level themes that any resulting design needs to address.
First, you need a way to generate and process a set of data structures that encompass the geometry, to allow you to trace rays against that geometry in an efficient manner. Secondly, when tracing rays, there’s some explicit user-defined programmability that can happen when the GPU has tested whether a ray intersects with it or not, meaning you need to execute user code. Thirdly, rays being traced can emit new rays! There are other things that a DXR implementation needs to take care of, but, in terms of the big picture then that trio of considerations are the most important.
Generating and consuming the acceleration structures for efficiently representing geometry that rays need to be tested against implies a potentially brand new phase of execution for the GPU to complete, and then we need to execute a brand new type of work primitive that processes those acceleration structures, test if they hit, and then do something under programmer control if they do or not. Think of it as a search problem, where rays are looking for things in the database of geometry.
And GPUs are parallel machines, so what does processing a bunch of rays together in that kind of way mean? Is it similar to the types of processing that GPUs are already heavily optimised for, or does doing so uncover new challenges that are substantially different to those baked into the traditional parallel processing of geometry and pixels?
The answer to that last question is a resounding yes, and the differences have a profound effect on how you want to map ray tracing onto a contemporary model of GPU execution. Today’s GPUs have a general imbalance of computational and memory resources, resulting in memory accesses being a precious commodity, and wasting these is one of the fastest ways to poor efficiency and poor performance.
Oh no – what have we done?
GPUs are designed to make the most of that access to connected memory in whatever form it takes, exploiting spatial or temporal locality of memory access as much as possible as the key to efficiency. Thankfully, most common and modern rasterised rendering has the nice property that during shading and especially pixel shading which is traditionally the dominant workload for any given frame, triangles and pixels will highly likely share some data with their immediate neighbours.
So, if you access any cache data needed by one group of pixels, say, chances are the next neighbouring group will need some or all of that memory you’ve already fetched from DRAM and cached. That holds true for most rasterised rendering workloads today, so we all get to heave a big sigh of relief and design GPUs around that property.
This is all great until we come to ray tracing. Ray tracing has the tendency to throw that property of spatial locality into the bin, fill the bin with petrol, and light the bin on fire. Let’s examine why.
Surface issues
The easiest way to think about it is to look around you and take note at what light is doing in your environment as you sit and read this. Since ray tracing typically models the properties of light as it propagates from all sources, it has to handle what happens when light hits any of the surfaces in the scene. Maybe we only care that the ray hits something, and what that something is. Maybe that surface scatters the light in a mostly uniform way, but maybe it’s almost completely random. Maybe the surface absorbs all of the light and it doesn’t go any further. Maybe the surface has a material that partially absorbs almost all of the light, and then randomly scatters the small amount of light that it doesn’t capture. You get the idea.
Only the first of those scenarios maps well to how a GPU tends to work when exploiting memory locality, and even then that’s only if all of the rays being processed in parallel all hit the same kind of triangles, and what happens during processing then is as uniform as possible.
It’s that potential for divergence that causes the problems. If any of the rays being processed in parallel might do anything differently from each other, including hitting a different bit of the acceleration structure, running different shading calculations, or starting new rays, the underlying model of how the GPU wants to work gets broken, and usually in more inefficient ways than the divergence you encounter in conventional geometry or pixel processing.
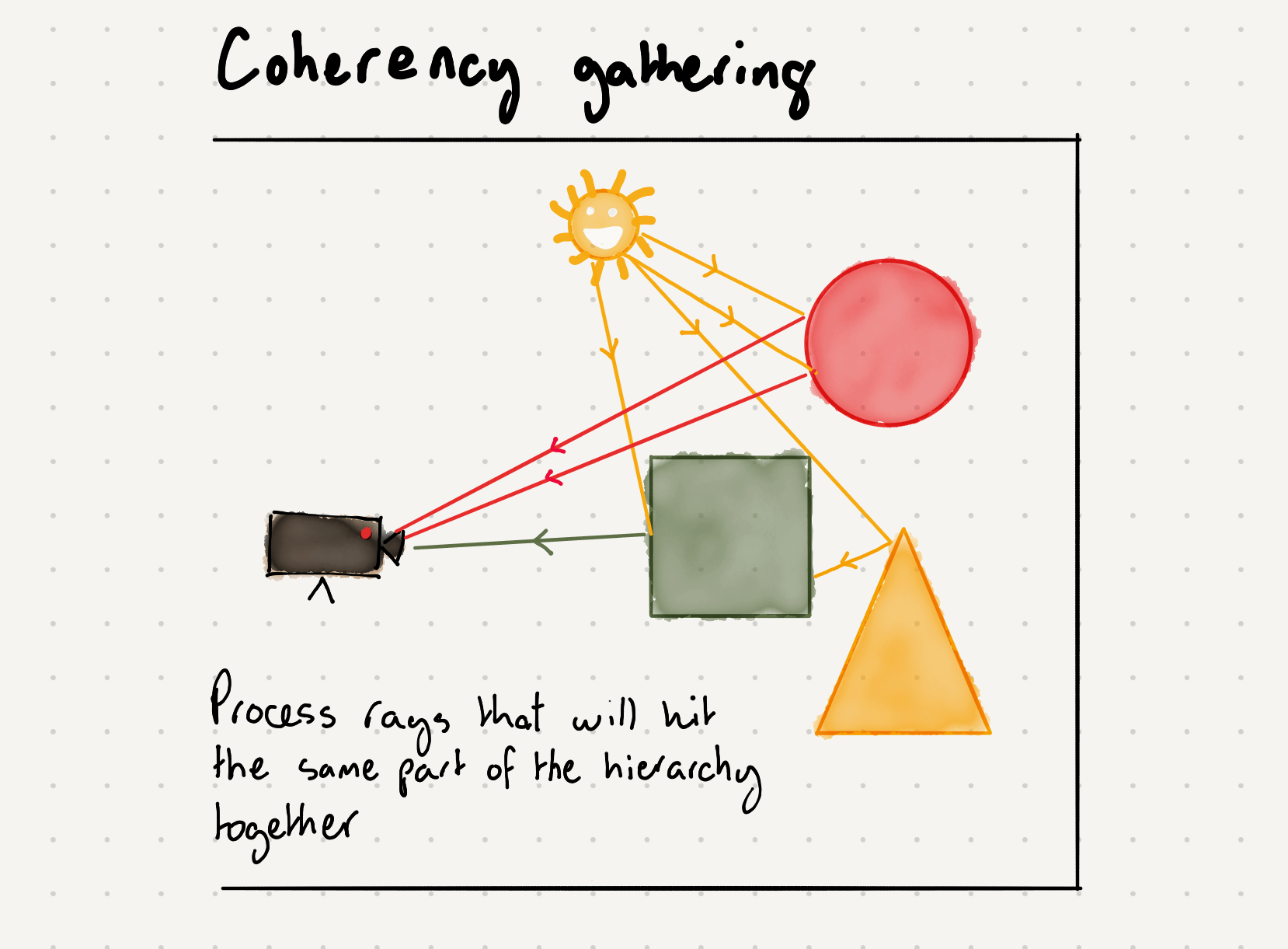
Coherency gathering
What PowerVR’s implementation of ray tracing hardware acceleration does, which is unique compared to any other hardware ray tracing acceleration on the market today, is hardware ray tracking and sorting, which, transparently to the software, makes sure that parallel dispatches of rays do have similar underlying properties when executed by the hardware. We call that coherency gathering. Other ray tracing solutions in the industry sometimes, but not always, do this crucial step in software, which is inevitably less efficient.
The hardware maintains a database of rays in flight that the game or app has launched and is able to select and group them by where they’re heading off to in the acceleration structure, based on their direction. This means that when they’re processed, they’re more likely to share the acceleration structure data being accessed in memory, with the added bonus of being able to maximise the amount of parallel ray-geometry intersections being performed by the GPU as testing occurs afterwards.
By analysing in-flight rays being scheduled by the hardware, we can make sure we group them for more efficient onward processing in a manner with which the GPU is already friendly. That’s key to the system’s success and helps maintain the hardware execution model the GPU industry trended towards while building today’s efficient rasterisers. That avoids the need for any specialise memory system just for the ray tracing hardware and therefore provides an easier integration path with the rest of the GPU machinery.

The coherency gathering machinery is itself pretty complex since it needs to quickly keep track of, sort and dispatch all of the in-flight rays in the system without causing either back pressure on the scheduler system that feeds it, starvation of the testing hardware that consumes the sorted rays being processed against the geometry acceleration structures, or poor use of the memory hierarchy in balance with other work happening on the machine at the same time.
Without that hardware system in place to help the GPU process similar rays you’re left either hoping that the application or game developer took care of ray coherency on the host somehow, or you’re shooting for some middle ground of sorting them on the GPU using compute programs – if the way you process rays in hardware even allows for that in the first place. None of those options is compelling for performance and efficiency in a real-time system, yet Imagination is the only GPU supplier on the market with such a system.
Note: at the time of re-publishing now in early 2023, that’s not really true any more. Intel and Nvidia have support for some level of application-controlled coherency gathering with hardware support. Nvidia have shader execution reordering, and Intel have a dedicated thread sorting unit that helps under certain conditions with some programming model-imposed limitations.
Going with the ray flow
PowerVR’s coherency gathering is compatible with today’s view of ray tracing, (including where a stack is unwound if rays happen to launch new rays, which themselves also might happen to launch new rays, and so on), gathering coherency at each dispatch step and ensuring we stay as close to the hardware’s possible ray flow as much as possible.
It’s also that ray flow which is most important to measure in a modern hardware ray tracer. Peak parallel testing rate, or empty ray launch and miss rate, are simple headlining ways to describe the performance of your ray tracing hardware, but they’re not terribly useful. After all, developers don’t only care about a high peak-parallel testing rate or a high miss-only rate.
The goal is usable full-fat ray flow throughout the entire accelerating system so that developers can do something useful with the ray budget you’re advertising. Our coherency gathering system allows us to offer that, making it unique compared to any other system on the market today.